Data lake(house)

Wij mogen bij veel organisaties een kijkje nemen in de ‘data-keuken’ en daaruit ontstaat het volgende beeld: bij de gemiddelde organisatie in Nederland wordt de data niet of slechts deels centraal vastgelegd. Bij organisaties die wel beschikken over een centrale dataopslag, voldoet deze vaak niet meer aan de (veranderde) wensen vanuit de organisatie. Zo is bijvoorbeeld een datawarehouse opgezet om dashboards te voeden, maar kan een data analist of data scientist niet met het datawarehouse uit de voeten en er niet de data uit halen die men wil. Ook wordt het datawarehouse vaak gevuld op basis van de informatie die in de dashboards dient te worden getoond, in plaats van dat alle data van de organisatie centraal wordt vastgelegd. Hierdoor wordt het bijvoorbeeld lastig of erg tijdsintensief om een spontane informatievraag te beantwoorden of snel een nieuw duurzaam inzicht te ontwikkelen op basis van data.
Maar hoe zorg je dan wel voor een moderne centrale dataopslag waarmee je borgt dat je zowel in je huidige als je toekomstige informatiebehoefte kunt voorzien? De ontwikkelingen op dat vlak volgen zich razendsnel op en zoals we gewend zijn binnen de IT, vliegen de termen je om de oren. Waar voor veel mensen een data lake nog klinkt als iets hypermoderns, hebben we het tegenwoordig alweer over de lakehouse architectuur.
Data is het nieuwe goud, maar zorgen we net zo goed voor onze data als voor onze waardevolle spullen?
Van datawarehouse tot lakehouse
Het datawarehouse
Een datawarehouse is een gestructureerde verzameling van gegevens die vooraf zijn gemodelleerd en geoptimaliseerd voor analyse en rapportage, veelal gebaseerd op een database management systeem. Deze vorm van opslag bestaat alweer sinds het einde van de jaren ’80. Een datawarehouse is geschikt voor bedrijven die hun gegevens willen gebruiken om dashboards te voeden en (mits goed ingericht) om self-service BI te bieden aan eindgebruikers.
Het data lake
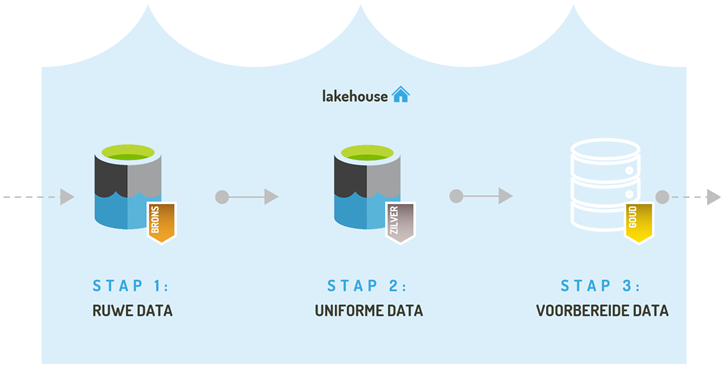
Maar voor complexere analyses en zaken als machine learning, is een data lake de juiste oplossing. Een data lake is een plek waar ruwe en ongestructureerde gegevens worden opgeslagen voor bijvoorbeeld toekomstig gebruik. Hiermee kan een datalake in de toekomst voorzien in een informatiebehoefte die er nu nog niet is. Blue-Mountain hanteert bij de implementatie van een datalake de zogenaamde ‘medallion archictecture’ waarbij data uit het datalake in twee verschillende vormen beschikbaar wordt gesteld:
Data lake ontsluiting volgens de medallion architecture
-
De bronzen laag deze laag biedt de daadwerkelijke ruwe en ongestructureerde gegevens
-
De zilveren laag in deze laag zijn de gegevens uit de bronzen laag ontdaan van dubbelingen en geüniformeerd qua outputformaat (deltalake) en inhoud (bijvoorbeeld één wijze van postcode notatie over alle bronnen heen)
Het data lakehouse
Maar wat is dan een data lakehouse? Een data lakehouse is een combinatie van een datawarehouse en een data lake, waar zowel gestructureerde als ongestructureerde gegevens worden opgeslagen en verwerkt met behulp van dezelfde technologie. Binnen een lake house wordt de data op een uiterst efficiënte manier opgeslagen en verwerkt waardoor de (cloud)kosten vaak lager zijn dan de kosten van enkel een klassiek data warehouse. Een data lakehouse is geschikt voor bedrijven die het beste van beide werelden willen combineren: de snelheid en betrouwbaarheid van een datawarehouse met de schaalbaarheid en flexibiliteit van een data lake. Wanneer we spreken over een lakehouse worden de bronzen en zilveren laag uit het datalake aangevuld met een zogenaamde gouden laag. Deze gouden laag vormt de output van het data warehouse deel en kan worden ingezet voor zaken als dashboarding, self-service en maken van voorspellende modellen.
| Data lakehouse | Data lake | Datawarehouse | |
|---|---|---|---|
| Gebruik | |||
| Use cases | Ad hoc analyse, data science, dashboarding en rapportages | Ad hoc analyse en data science | Dashboarding en rapportages |
| Type gebruiker | Data analist, Data scientist en Eindgebruiker | Data analist, Data scientist | Eindgebruiker |
| Techniek | |||
| Type data | On- en gestructureerd | Ongestructureerd | Gestructureerd |
| Data snelkoppelingen beschikbaar | Ja | Ja | |
| Data organisatie | Mappen en bestanden, databases en tabellen | Mappen en bestanden | Databases en tabellen |
Waarom een data lake(house) van Blue-Mountain?
-
Modulaire opbouw Een goed dataplatform vormt een stabiele basis in het informatie- en applicatielandschap. Om deze continuïteit te kunnen garanderen moet het platform kunnen meebewegen met toekomstige ontwikkelingen (en die gaan heel hard!). Het dataplatform van Blue-Mountain is opgebouwd uit losse modules (op zowel software- als codeniveau) die zonder al te grote impact kunnen worden vervangen wanneer er, voor dat stukje van de data voorbereiding, een beter alternatief beschikbaar komt.
-
Gebouwd op (open) standaarden Het dataplatform is gebouwd op open standaarden en proven technology met een brede bestaande gebruikersbasis. Hierdoor ben je voor de doorontwikkeling of het beheer nooit afhankelijk van de continuïteit of kwaliteit van dienstverlening van een enkele partij.
-
Gebouwd op sector standaarden Voor algemene informatiedomeinen als financiën, HRM en ICT beschikt het data platform over standaard sjablonen voor de 'gouden laag' die elke organisatie in staat stelt om een vliegende start te maken. Daarnaast bieden wij voor woningcorporaties, de zorg en het onderwijs sector specifieke sjablonen over relevante onderwerpen zoals verhuur of onderwijskwaliteit. Uiteraard zijn deze sjablonen volledig gebaseerd op sectorstandaarden zoals CORA, VERA of FORA.
Schrijf je in voor een gratis webinar!
We organiseren regelmatig webinars waarbij we je in een half uurtje meenemen in het data lake(house) van Blue-Mountain. Wil je zo'n webinar bijwonen? Laat dan hiernaast je e-mail adres achter.
 Jeroen Hock
Jeroen Hock